#linux terminal guide
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Premium Tumblr themes are available from anywhere between $9 to $49.
Video
youtube
Getting Started with Linux Commands | ls cp pwd less more id tty date rm...
#youtube#Welcome to our comprehensive guide on Getting Started with Linux Commands! 🐧 In this tutorial we’ll walk you through essential Linux termin
0 notes
Text
How I ditched streaming services and learned to love Linux: A step-by-step guide to building your very own personal media streaming server (V2.0: REVISED AND EXPANDED EDITION)
This is a revised, corrected and expanded version of my tutorial on setting up a personal media server that previously appeared on my old blog (donjuan-auxenfers). I expect that that post is still making the rounds (hopefully with my addendum on modifying group share permissions in Ubuntu to circumvent 0x8007003B "Unexpected Network Error" messages in Windows 10/11 when transferring files) but I have no way of checking. Anyway this new revised version of the tutorial corrects one or two small errors I discovered when rereading what I wrote, adds links to all products mentioned and is just more polished generally. I also expanded it a bit, pointing more adventurous users toward programs such as Sonarr/Radarr/Lidarr and Overseerr which can be used for automating user requests and media collection.
So then, what is this tutorial? This is a tutorial on how to build and set up your own personal media server using Ubuntu as an operating system and Plex (or Jellyfin) to not only manage your media, but to also stream that media to your devices both at home and abroad anywhere in the world where you have an internet connection. Its intent is to show you how building a personal media server and stuffing it full of films, TV, and music that you acquired through indiscriminate and voracious media piracy various legal methods will free you to completely ditch paid streaming services. No more will you have to pay for Disney+, Netflix, HBOMAX, Hulu, Amazon Prime, Peacock, CBS All Access, Paramount+, Crave or any other streaming service that is not named Criterion Channel. Instead whenever you want to watch your favourite films and television shows, you’ll have your own personal service that only features things that you want to see, with files that you have control over. And for music fans out there, both Jellyfin and Plex support music streaming, meaning you can even ditch music streaming services. Goodbye Spotify, Youtube Music, Tidal and Apple Music, welcome back unreasonably large MP3 (or FLAC) collections.
On the hardware front, I’m going to offer a few options catered towards different budgets and media library sizes. The cost of getting a media server up and running using this guide will cost you anywhere from $450 CAD/$325 USD at the low end to $1500 CAD/$1100 USD at the high end (it could go higher). My server was priced closer to the higher figure, but I went and got a lot more storage than most people need. If that seems like a little much, consider for a moment, do you have a roommate, a close friend, or a family member who would be willing to chip in a few bucks towards your little project provided they get access? Well that's how I funded my server. It might also be worth thinking about the cost over time, i.e. how much you spend yearly on subscriptions vs. a one time cost of setting up a server. Additionally there's just the joy of being able to scream "fuck you" at all those show cancelling, library deleting, hedge fund vampire CEOs who run the studios through denying them your money. Drive a stake through David Zaslav's heart.
On the software side I will walk you step-by-step through installing Ubuntu as your server's operating system, configuring your storage as a RAIDz array with ZFS, sharing your zpool to Windows with Samba, running a remote connection between your server and your Windows PC, and then a little about started with Plex/Jellyfin. Every terminal command you will need to input will be provided, and I even share a custom #bash script that will make used vs. available drive space on your server display correctly in Windows.
If you have a different preferred flavour of Linux (Arch, Manjaro, Redhat, Fedora, Mint, OpenSUSE, CentOS, Slackware etc. et. al.) and are aching to tell me off for being basic and using Ubuntu, this tutorial is not for you. The sort of person with a preferred Linux distro is the sort of person who can do this sort of thing in their sleep. Also I don't care. This tutorial is intended for the average home computer user. This is also why we’re not using a more exotic home server solution like running everything through Docker Containers and managing it through a dashboard like Homarr or Heimdall. While such solutions are fantastic and can be very easy to maintain once you have it all set up, wrapping your brain around Docker is a whole thing in and of itself. If you do follow this tutorial and had fun putting everything together, then I would encourage you to return in a year’s time, do your research and set up everything with Docker Containers.
Lastly, this is a tutorial aimed at Windows users. Although I was a daily user of OS X for many years (roughly 2008-2023) and I've dabbled quite a bit with various Linux distributions (mostly Ubuntu and Manjaro), my primary OS these days is Windows 11. Many things in this tutorial will still be applicable to Mac users, but others (e.g. setting up shares) you will have to look up for yourself. I doubt it would be difficult to do so.
Nothing in this tutorial will require feats of computing expertise. All you will need is a basic computer literacy (i.e. an understanding of what a filesystem and directory are, and a degree of comfort in the settings menu) and a willingness to learn a thing or two. While this guide may look overwhelming at first glance, it is only because I want to be as thorough as possible. I want you to understand exactly what it is you're doing, I don't want you to just blindly follow steps. If you half-way know what you’re doing, you will be much better prepared if you ever need to troubleshoot.
Honestly, once you have all the hardware ready it shouldn't take more than an afternoon or two to get everything up and running.
(This tutorial is just shy of seven thousand words long so the rest is under the cut.)
Step One: Choosing Your Hardware
Linux is a light weight operating system, depending on the distribution there's close to no bloat. There are recent distributions available at this very moment that will run perfectly fine on a fourteen year old i3 with 4GB of RAM. Moreover, running Plex or Jellyfin isn’t resource intensive in 90% of use cases. All this is to say, we don’t require an expensive or powerful computer. This means that there are several options available: 1) use an old computer you already have sitting around but aren't using 2) buy a used workstation from eBay, or what I believe to be the best option, 3) order an N100 Mini-PC from AliExpress or Amazon.
Note: If you already have an old PC sitting around that you’ve decided to use, fantastic, move on to the next step.
When weighing your options, keep a few things in mind: the number of people you expect to be streaming simultaneously at any one time, the resolution and bitrate of your media library (4k video takes a lot more processing power than 1080p) and most importantly, how many of those clients are going to be transcoding at any one time. Transcoding is what happens when the playback device does not natively support direct playback of the source file. This can happen for a number of reasons, such as the playback device's native resolution being lower than the file's internal resolution, or because the source file was encoded in a video codec unsupported by the playback device.
Ideally we want any transcoding to be performed by hardware. This means we should be looking for a computer with an Intel processor with Quick Sync. Quick Sync is a dedicated core on the CPU die designed specifically for video encoding and decoding. This specialized hardware makes for highly efficient transcoding both in terms of processing overhead and power draw. Without these Quick Sync cores, transcoding must be brute forced through software. This takes up much more of a CPU’s processing power and requires much more energy. But not all Quick Sync cores are created equal and you need to keep this in mind if you've decided either to use an old computer or to shop for a used workstation on eBay
Any Intel processor from second generation Core (Sandy Bridge circa 2011) onward has Quick Sync cores. It's not until 6th gen (Skylake), however, that the cores support the H.265 HEVC codec. Intel’s 10th gen (Comet Lake) processors introduce support for 10bit HEVC and HDR tone mapping. And the recent 12th gen (Alder Lake) processors brought with them hardware AV1 decoding. As an example, while an 8th gen (Kaby Lake) i5-8500 will be able to hardware transcode a H.265 encoded file, it will fall back to software transcoding if given a 10bit H.265 file. If you’ve decided to use that old PC or to look on eBay for an old Dell Optiplex keep this in mind.
Note 1: The price of old workstations varies wildly and fluctuates frequently. If you get lucky and go shopping shortly after a workplace has liquidated a large number of their workstations you can find deals for as low as $100 on a barebones system, but generally an i5-8500 workstation with 16gb RAM will cost you somewhere in the area of $260 CAD/$200 USD.
Note 2: The AMD equivalent to Quick Sync is called Video Core Next, and while it's fine, it's not as efficient and not as mature a technology. It was only introduced with the first generation Ryzen CPUs and it only got decent with their newest CPUs, we want something cheap.
Alternatively you could forgo having to keep track of what generation of CPU is equipped with Quick Sync cores that feature support for which codecs, and just buy an N100 mini-PC. For around the same price or less of a used workstation you can pick up a mini-PC with an Intel N100 processor. The N100 is a four-core processor based on the 12th gen Alder Lake architecture and comes equipped with the latest revision of the Quick Sync cores. These little processors offer astounding hardware transcoding capabilities for their size and power draw. Otherwise they perform equivalent to an i5-6500, which isn't a terrible CPU. A friend of mine uses an N100 machine as a dedicated retro emulation gaming system and it does everything up to 6th generation consoles just fine. The N100 is also a remarkably efficient chip, it sips power. In fact, the difference between running one of these and an old workstation could work out to hundreds of dollars a year in energy bills depending on where you live.
You can find these Mini-PCs all over Amazon or for a little cheaper on AliExpress. They range in price from $170 CAD/$125 USD for a no name N100 with 8GB RAM to $280 CAD/$200 USD for a Beelink S12 Pro with 16GB RAM. The brand doesn't really matter, they're all coming from the same three factories in Shenzen, go for whichever one fits your budget or has features you want. 8GB RAM should be enough, Linux is lightweight and Plex only calls for 2GB RAM. 16GB RAM might result in a slightly snappier experience, especially with ZFS. A 256GB SSD is more than enough for what we need as a boot drive, but going for a bigger drive might allow you to get away with things like creating preview thumbnails for Plex, but it’s up to you and your budget.
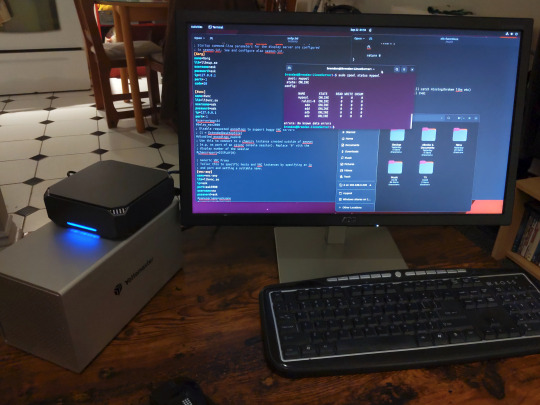
The Mini-PC I wound up buying was a Firebat AK2 Plus with 8GB RAM and a 256GB SSD. It looks like this:

Note: Be forewarned that if you decide to order a Mini-PC from AliExpress, note the type of power adapter it ships with. The mini-PC I bought came with an EU power adapter and I had to supply my own North American power supply. Thankfully this is a minor issue as barrel plug 30W/12V/2.5A power adapters are easy to find and can be had for $10.
Step Two: Choosing Your Storage
Storage is the most important part of our build. It is also the most expensive. Thankfully it’s also the most easily upgrade-able down the line.
For people with a smaller media collection (4TB to 8TB), a more limited budget, or who will only ever have two simultaneous streams running, I would say that the most economical course of action would be to buy a USB 3.0 8TB external HDD. Something like this one from Western Digital or this one from Seagate. One of these external drives will cost you in the area of $200 CAD/$140 USD. Down the line you could add a second external drive or replace it with a multi-drive RAIDz set up such as detailed below.
If a single external drive the path for you, move on to step three.
For people with larger media libraries (12TB+), who prefer media in 4k, or care who about data redundancy, the answer is a RAID array featuring multiple HDDs in an enclosure.
Note: If you are using an old PC or used workstatiom as your server and have the room for at least three 3.5" drives, and as many open SATA ports on your mother board you won't need an enclosure, just install the drives into the case. If your old computer is a laptop or doesn’t have room for more internal drives, then I would suggest an enclosure.
The minimum number of drives needed to run a RAIDz array is three, and seeing as RAIDz is what we will be using, you should be looking for an enclosure with three to five bays. I think that four disks makes for a good compromise for a home server. Regardless of whether you go for a three, four, or five bay enclosure, do be aware that in a RAIDz array the space equivalent of one of the drives will be dedicated to parity at a ratio expressed by the equation 1 − 1/n i.e. in a four bay enclosure equipped with four 12TB drives, if we configured our drives in a RAIDz1 array we would be left with a total of 36TB of usable space (48TB raw size). The reason for why we might sacrifice storage space in such a manner will be explained in the next section.
A four bay enclosure will cost somewhere in the area of $200 CDN/$140 USD. You don't need anything fancy, we don't need anything with hardware RAID controls (RAIDz is done entirely in software) or even USB-C. An enclosure with USB 3.0 will perform perfectly fine. Don’t worry too much about USB speed bottlenecks. A mechanical HDD will be limited by the speed of its mechanism long before before it will be limited by the speed of a USB connection. I've seen decent looking enclosures from TerraMaster, Yottamaster, Mediasonic and Sabrent.
When it comes to selecting the drives, as of this writing, the best value (dollar per gigabyte) are those in the range of 12TB to 20TB. I settled on 12TB drives myself. If 12TB to 20TB drives are out of your budget, go with what you can afford, or look into refurbished drives. I'm not sold on the idea of refurbished drives but many people swear by them.
When shopping for harddrives, search for drives designed specifically for NAS use. Drives designed for NAS use typically have better vibration dampening and are designed to be active 24/7. They will also often make use of CMR (conventional magnetic recording) as opposed to SMR (shingled magnetic recording). This nets them a sizable read/write performance bump over typical desktop drives. Seagate Ironwolf and Toshiba NAS are both well regarded brands when it comes to NAS drives. I would avoid Western Digital Red drives at this time. WD Reds were a go to recommendation up until earlier this year when it was revealed that they feature firmware that will throw up false SMART warnings telling you to replace the drive at the three year mark quite often when there is nothing at all wrong with that drive. It will likely even be good for another six, seven, or more years.

Step Three: Installing Linux
For this step you will need a USB thumbdrive of at least 6GB in capacity, an .ISO of Ubuntu, and a way to make that thumbdrive bootable media.
First download a copy of Ubuntu desktop (for best performance we could download the Server release, but for new Linux users I would recommend against the server release. The server release is strictly command line interface only, and having a GUI is very helpful for most people. Not many people are wholly comfortable doing everything through the command line, I'm certainly not one of them, and I grew up with DOS 6.0. 22.04.3 Jammy Jellyfish is the current Long Term Service release, this is the one to get.
Download the .ISO and then download and install balenaEtcher on your Windows PC. BalenaEtcher is an easy to use program for creating bootable media, you simply insert your thumbdrive, select the .ISO you just downloaded, and it will create a bootable installation media for you.
Once you've made a bootable media and you've got your Mini-PC (or you old PC/used workstation) in front of you, hook it directly into your router with an ethernet cable, and then plug in the HDD enclosure, a monitor, a mouse and a keyboard. Now turn that sucker on and hit whatever key gets you into the BIOS (typically ESC, DEL or F2). If you’re using a Mini-PC check to make sure that the P1 and P2 power limits are set correctly, my N100's P1 limit was set at 10W, a full 20W under the chip's power limit. Also make sure that the RAM is running at the advertised speed. My Mini-PC’s RAM was set at 2333Mhz out of the box when it should have been 3200Mhz. Once you’ve done that, key over to the boot order and place the USB drive first in the boot order. Then save the BIOS settings and restart.
After you restart you’ll be greeted by Ubuntu's installation screen. Installing Ubuntu is really straight forward, select the "minimal" installation option, as we won't need anything on this computer except for a browser (Ubuntu comes preinstalled with Firefox) and Plex Media Server/Jellyfin Media Server. Also remember to delete and reformat that Windows partition! We don't need it.
Step Four: Installing ZFS and Setting Up the RAIDz Array
Note: If you opted for just a single external HDD skip this step and move onto setting up a Samba share.
Once Ubuntu is installed it's time to configure our storage by installing ZFS to build our RAIDz array. ZFS is a "next-gen" file system that is both massively flexible and massively complex. It's capable of snapshot backup, self healing error correction, ZFS pools can be configured with drives operating in a supplemental manner alongside the storage vdev (e.g. fast cache, dedicated secondary intent log, hot swap spares etc.). It's also a file system very amenable to fine tuning. Block and sector size are adjustable to use case and you're afforded the option of different methods of inline compression. If you'd like a very detailed overview and explanation of its various features and tips on tuning a ZFS array check out these articles from Ars Technica. For now we're going to ignore all these features and keep it simple, we're going to pull our drives together into a single vdev running in RAIDz which will be the entirety of our zpool, no fancy cache drive or SLOG.
Open up the terminal and type the following commands:
sudo apt update
then
sudo apt install zfsutils-linux
This will install the ZFS utility. Verify that it's installed with the following command:
zfs --version
Now, it's time to check that the HDDs we have in the enclosure are healthy, running, and recognized. We also want to find out their device IDs and take note of them:
sudo fdisk -1
Note: You might be wondering why some of these commands require "sudo" in front of them while others don't. "Sudo" is short for "super user do”. When and where "sudo" is used has to do with the way permissions are set up in Linux. Only the "root" user has the access level to perform certain tasks in Linux. As a matter of security and safety regular user accounts are kept separate from the "root" user. It's not advised (or even possible) to boot into Linux as "root" with most modern distributions. Instead by using "sudo" our regular user account is temporarily given the power to do otherwise forbidden things. Don't worry about it too much at this stage, but if you want to know more check out this introduction.
If everything is working you should get a list of the various drives detected along with their device IDs which will look like this: /dev/sdc. You can also check the device IDs of the drives by opening the disk utility app. Jot these IDs down as we'll need them for our next step, creating our RAIDz array.
RAIDz is similar to RAID-5 in that instead of striping your data over multiple disks, exchanging redundancy for speed and available space (RAID-0), or mirroring your data writing by two copies of every piece (RAID-1), it instead writes parity blocks across the disks in addition to striping, this provides a balance of speed, redundancy and available space. If a single drive fails, the parity blocks on the working drives can be used to reconstruct the entire array as soon as a replacement drive is added.
Additionally, RAIDz improves over some of the common RAID-5 flaws. It's more resilient and capable of self healing, as it is capable of automatically checking for errors against a checksum. It's more forgiving in this way, and it's likely that you'll be able to detect when a drive is dying well before it fails. A RAIDz array can survive the loss of any one drive.
Note: While RAIDz is indeed resilient, if a second drive fails during the rebuild, you're fucked. Always keep backups of things you can't afford to lose. This tutorial, however, is not about proper data safety.
To create the pool, use the following command:
sudo zpool create "zpoolnamehere" raidz "device IDs of drives we're putting in the pool"
For example, let's creatively name our zpool "mypool". This poil will consist of four drives which have the device IDs: sdb, sdc, sdd, and sde. The resulting command will look like this:
sudo zpool create mypool raidz /dev/sdb /dev/sdc /dev/sdd /dev/sde
If as an example you bought five HDDs and decided you wanted more redundancy dedicating two drive to this purpose, we would modify the command to "raidz2" and the command would look something like the following:
sudo zpool create mypool raidz2 /dev/sdb /dev/sdc /dev/sdd /dev/sde /dev/sdf
An array configured like this is known as RAIDz2 and is able to survive two disk failures.
Once the zpool has been created, we can check its status with the command:
zpool status
Or more concisely with:
zpool list
The nice thing about ZFS as a file system is that a pool is ready to go immediately after creation. If we were to set up a traditional RAID-5 array using mbam, we'd have to sit through a potentially hours long process of reformatting and partitioning the drives. Instead we're ready to go right out the gates.
The zpool should be automatically mounted to the filesystem after creation, check on that with the following:
df -hT | grep zfs
Note: If your computer ever loses power suddenly, say in event of a power outage, you may have to re-import your pool. In most cases, ZFS will automatically import and mount your pool, but if it doesn’t and you can't see your array, simply open the terminal and type sudo zpool import -a.
By default a zpool is mounted at /"zpoolname". The pool should be under our ownership but let's make sure with the following command:
sudo chown -R "yourlinuxusername" /"zpoolname"
Note: Changing file and folder ownership with "chown" and file and folder permissions with "chmod" are essential commands for much of the admin work in Linux, but we won't be dealing with them extensively in this guide. If you'd like a deeper tutorial and explanation you can check out these two guides: chown and chmod.
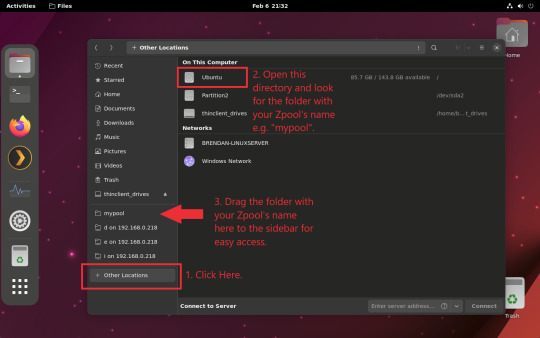
You can access the zpool file system through the GUI by opening the file manager (the Ubuntu default file manager is called Nautilus) and clicking on "Other Locations" on the sidebar, then entering the Ubuntu file system and looking for a folder with your pool's name. Bookmark the folder on the sidebar for easy access.
Your storage pool is now ready to go. Assuming that we already have some files on our Windows PC we want to copy to over, we're going to need to install and configure Samba to make the pool accessible in Windows.
Step Five: Setting Up Samba/Sharing
Samba is what's going to let us share the zpool with Windows and allow us to write to it from our Windows machine. First let's install Samba with the following commands:
sudo apt-get update
then
sudo apt-get install samba
Next create a password for Samba.
sudo smbpswd -a "yourlinuxusername"
It will then prompt you to create a password. Just reuse your Ubuntu user password for simplicity's sake.
Note: if you're using just a single external drive replace the zpool location in the following commands with wherever it is your external drive is mounted, for more information see this guide on mounting an external drive in Ubuntu.
After you've created a password we're going to create a shareable folder in our pool with this command
mkdir /"zpoolname"/"foldername"
Now we're going to open the smb.conf file and make that folder shareable. Enter the following command.
sudo nano /etc/samba/smb.conf
This will open the .conf file in nano, the terminal text editor program. Now at the end of smb.conf add the following entry:
["foldername"]
path = /"zpoolname"/"foldername"
available = yes
valid users = "yourlinuxusername"
read only = no
writable = yes
browseable = yes
guest ok = no
Ensure that there are no line breaks between the lines and that there's a space on both sides of the equals sign. Our next step is to allow Samba traffic through the firewall:
sudo ufw allow samba
Finally restart the Samba service:
sudo systemctl restart smbd
At this point we'll be able to access to the pool, browse its contents, and read and write to it from Windows. But there's one more thing left to do, Windows doesn't natively support the ZFS file systems and will read the used/available/total space in the pool incorrectly. Windows will read available space as total drive space, and all used space as null. This leads to Windows only displaying a dwindling amount of "available" space as the drives are filled. We can fix this! Functionally this doesn't actually matter, we can still write and read to and from the disk, it just makes it difficult to tell at a glance the proportion of used/available space, so this is an optional step but one I recommend (this step is also unnecessary if you're just using a single external drive). What we're going to do is write a little shell script in #bash. Open nano with the terminal with the command:
nano
Now insert the following code:
#!/bin/bash CUR_PATH=`pwd` ZFS_CHECK_OUTPUT=$(zfs get type $CUR_PATH 2>&1 > /dev/null) > /dev/null if [[ $ZFS_CHECK_OUTPUT == *not\ a\ ZFS* ]] then IS_ZFS=false else IS_ZFS=true fi if [[ $IS_ZFS = false ]] then df $CUR_PATH | tail -1 | awk '{print $2" "$4}' else USED=$((`zfs get -o value -Hp used $CUR_PATH` / 1024)) > /dev/null AVAIL=$((`zfs get -o value -Hp available $CUR_PATH` / 1024)) > /dev/null TOTAL=$(($USED+$AVAIL)) > /dev/null echo $TOTAL $AVAIL fi
Save the script as "dfree.sh" to /home/"yourlinuxusername" then change the ownership of the file to make it executable with this command:
sudo chmod 774 dfree.sh
Now open smb.conf with sudo again:
sudo nano /etc/samba/smb.conf
Now add this entry to the top of the configuration file to direct Samba to use the results of our script when Windows asks for a reading on the pool's used/available/total drive space:
[global]
dfree command = /home/"yourlinuxusername"/dfree.sh
Save the changes to smb.conf and then restart Samba again with the terminal:
sudo systemctl restart smbd
Now there’s one more thing we need to do to fully set up the Samba share, and that’s to modify a hidden group permission. In the terminal window type the following command:
usermod -a -G sambashare “yourlinuxusername”
Then restart samba again:
sudo systemctl restart smbd
If we don’t do this last step, everything will appear to work fine, and you will even be able to see and map the drive from Windows and even begin transferring files, but you'd soon run into a lot of frustration. As every ten minutes or so a file would fail to transfer and you would get a window announcing “0x8007003B Unexpected Network Error”. This window would require your manual input to continue the transfer with the file next in the queue. And at the end it would reattempt to transfer whichever files failed the first time around. 99% of the time they’ll go through that second try, but this is still all a major pain in the ass. Especially if you’ve got a lot of data to transfer or you want to step away from the computer for a while.
It turns out samba can act a little weirdly with the higher read/write speeds of RAIDz arrays and transfers from Windows, and will intermittently crash and restart itself if this group option isn’t changed. Inputting the above command will prevent you from ever seeing that window.
The last thing we're going to do before switching over to our Windows PC is grab the IP address of our Linux machine. Enter the following command:
hostname -I
This will spit out this computer's IP address on the local network (it will look something like 192.168.0.x), write it down. It might be a good idea once you're done here to go into your router settings and reserving that IP for your Linux system in the DHCP settings. Check the manual for your specific model router on how to access its settings, typically it can be accessed by opening a browser and typing http:\\192.168.0.1 in the address bar, but your router may be different.
Okay we’re done with our Linux computer for now. Get on over to your Windows PC, open File Explorer, right click on Network and click "Map network drive". Select Z: as the drive letter (you don't want to map the network drive to a letter you could conceivably be using for other purposes) and enter the IP of your Linux machine and location of the share like so: \\"LINUXCOMPUTERLOCALIPADDRESSGOESHERE"\"zpoolnamegoeshere"\. Windows will then ask you for your username and password, enter the ones you set earlier in Samba and you're good. If you've done everything right it should look something like this:

You can now start moving media over from Windows to the share folder. It's a good idea to have a hard line running to all machines. Moving files over Wi-Fi is going to be tortuously slow, the only thing that’s going to make the transfer time tolerable (hours instead of days) is a solid wired connection between both machines and your router.
Step Six: Setting Up Remote Desktop Access to Your Server
After the server is up and going, you’ll want to be able to access it remotely from Windows. Barring serious maintenance/updates, this is how you'll access it most of the time. On your Linux system open the terminal and enter:
sudo apt install xrdp
Then:
sudo systemctl enable xrdp
Once it's finished installing, open “Settings” on the sidebar and turn off "automatic login" in the User category. Then log out of your account. Attempting to remotely connect to your Linux computer while you’re logged in will result in a black screen!
Now get back on your Windows PC, open search and look for "RDP". A program called "Remote Desktop Connection" should pop up, open this program as an administrator by right-clicking and selecting “run as an administrator”. You’ll be greeted with a window. In the field marked “Computer” type in the IP address of your Linux computer. Press connect and you'll be greeted with a new window and prompt asking for your username and password. Enter your Ubuntu username and password here.
If everything went right, you’ll be logged into your Linux computer. If the performance is sluggish, adjust the display options. Lowering the resolution and colour depth do a lot to make the interface feel snappier.
Remote access is how we're going to be using our Linux system from now, barring edge cases like needing to get into the BIOS or upgrading to a new version of Ubuntu. Everything else from performing maintenance like a monthly zpool scrub to checking zpool status and updating software can all be done remotely.

This is how my server lives its life now, happily humming and chirping away on the floor next to the couch in a corner of the living room.
Step Seven: Plex Media Server/Jellyfin
Okay we’ve got all the ground work finished and our server is almost up and running. We’ve got Ubuntu up and running, our storage array is primed, we’ve set up remote connections and sharing, and maybe we’ve moved over some of favourite movies and TV shows.
Now we need to decide on the media server software to use which will stream our media to us and organize our library. For most people I’d recommend Plex. It just works 99% of the time. That said, Jellyfin has a lot to recommend it by too, even if it is rougher around the edges. Some people run both simultaneously, it’s not that big of an extra strain. I do recommend doing a little bit of your own research into the features each platform offers, but as a quick run down, consider some of the following points:
Plex is closed source and is funded through PlexPass purchases while Jellyfin is open source and entirely user driven. This means a number of things: for one, Plex requires you to purchase a “PlexPass” (purchased as a one time lifetime fee $159.99 CDN/$120 USD or paid for on a monthly or yearly subscription basis) in order to access to certain features, like hardware transcoding (and we want hardware transcoding) or automated intro/credits detection and skipping, Jellyfin offers some of these features for free through plugins. Plex supports a lot more devices than Jellyfin and updates more frequently. That said, Jellyfin's Android and iOS apps are completely free, while the Plex Android and iOS apps must be activated for a one time cost of $6 CDN/$5 USD. But that $6 fee gets you a mobile app that is much more functional and features a unified UI across platforms, the Plex mobile apps are simply a more polished experience. The Jellyfin apps are a bit of a mess and the iOS and Android versions are very different from each other.
Jellyfin’s actual media player is more fully featured than Plex's, but on the other hand Jellyfin's UI, library customization and automatic media tagging really pale in comparison to Plex. Streaming your music library is free through both Jellyfin and Plex, but Plex offers the PlexAmp app for dedicated music streaming which boasts a number of fantastic features, unfortunately some of those fantastic features require a PlexPass. If your internet is down, Jellyfin can still do local streaming, while Plex can fail to play files unless you've got it set up a certain way. Jellyfin has a slew of neat niche features like support for Comic Book libraries with the .cbz/.cbt file types, but then Plex offers some free ad-supported TV and films, they even have a free channel that plays nothing but Classic Doctor Who.
Ultimately it's up to you, I settled on Plex because although some features are pay-walled, it just works. It's more reliable and easier to use, and a one-time fee is much easier to swallow than a subscription. I had a pretty easy time getting my boomer parents and tech illiterate brother introduced to and using Plex and I don't know if I would've had as easy a time doing that with Jellyfin. I do also need to mention that Jellyfin does take a little extra bit of tinkering to get going in Ubuntu, you’ll have to set up process permissions, so if you're more tolerant to tinkering, Jellyfin might be up your alley and I’ll trust that you can follow their installation and configuration guide. For everyone else, I recommend Plex.
So pick your poison: Plex or Jellyfin.
Note: The easiest way to download and install either of these packages in Ubuntu is through Snap Store.
After you've installed one (or both), opening either app will launch a browser window into the browser version of the app allowing you to set all the options server side.
The process of adding creating media libraries is essentially the same in both Plex and Jellyfin. You create a separate libraries for Television, Movies, and Music and add the folders which contain the respective types of media to their respective libraries. The only difficult or time consuming aspect is ensuring that your files and folders follow the appropriate naming conventions:
Plex naming guide for Movies
Plex naming guide for Television
Jellyfin follows the same naming rules but I find their media scanner to be a lot less accurate and forgiving than Plex. Once you've selected the folders to be scanned the service will scan your files, tagging everything and adding metadata. Although I find do find Plex more accurate, it can still erroneously tag some things and you might have to manually clean up some tags in a large library. (When I initially created my library it tagged the 1963-1989 Doctor Who as some Korean soap opera and I needed to manually select the correct match after which everything was tagged normally.) It can also be a bit testy with anime (especially OVAs) be sure to check TVDB to ensure that you have your files and folders structured and named correctly. If something is not showing up at all, double check the name.
Once that's done, organizing and customizing your library is easy. You can set up collections, grouping items together to fit a theme or collect together all the entries in a franchise. You can make playlists, and add custom artwork to entries. It's fun setting up collections with posters to match, there are even several websites dedicated to help you do this like PosterDB. As an example, below are two collections in my library, one collecting all the entries in a franchise, the other follows a theme.

My Star Trek collection, featuring all eleven television series, and thirteen films.
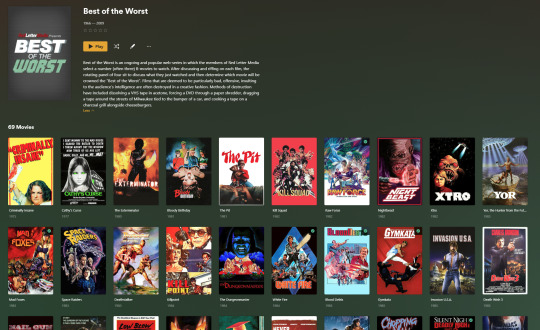
My Best of the Worst collection, featuring sixty-nine films previously showcased on RedLetterMedia’s Best of the Worst. They’re all absolutely terrible and I love them.
As for settings, ensure you've got Remote Access going, it should work automatically and be sure to set your upload speed after running a speed test. In the library settings set the database cache to 2000MB to ensure a snappier and more responsive browsing experience, and then check that playback quality is set to original/maximum. If you’re severely bandwidth limited on your upload and have remote users, you might want to limit the remote stream bitrate to something more reasonable, just as a note of comparison Netflix’s 1080p bitrate is approximately 5Mbps, although almost anyone watching through a chromium based browser is streaming at 720p and 3mbps. Other than that you should be good to go. For actually playing your files, there's a Plex app for just about every platform imaginable. I mostly watch television and films on my laptop using the Windows Plex app, but I also use the Android app which can broadcast to the chromecast connected to the TV in the office and the Android TV app for our smart TV. Both are fully functional and easy to navigate, and I can also attest to the OS X version being equally functional.
Part Eight: Finding Media
Now, this is not really a piracy tutorial, there are plenty of those out there. But if you’re unaware, BitTorrent is free and pretty easy to use, just pick a client (qBittorrent is the best) and go find some public trackers to peruse. Just know now that all the best trackers are private and invite only, and that they can be exceptionally difficult to get into. I’m already on a few, and even then, some of the best ones are wholly out of my reach.
If you decide to take the left hand path and turn to Usenet you’ll have to pay. First you’ll need to sign up with a provider like Newshosting or EasyNews for access to Usenet itself, and then to actually find anything you’re going to need to sign up with an indexer like NZBGeek or NZBFinder. There are dozens of indexers, and many people cross post between them, but for more obscure media it’s worth checking multiple. You’ll also need a binary downloader like SABnzbd. That caveat aside, Usenet is faster, bigger, older, less traceable than BitTorrent, and altogether slicker. I honestly prefer it, and I'm kicking myself for taking this long to start using it because I was scared off by the price. I’ve found so many things on Usenet that I had sought in vain elsewhere for years, like a 2010 Italian film about a massacre perpetrated by the SS that played the festival circuit but never received a home media release; some absolute hero uploaded a rip of a festival screener DVD to Usenet. Anyway, figure out the rest of this shit on your own and remember to use protection, get yourself behind a VPN, use a SOCKS5 proxy with your BitTorrent client, etc.
On the legal side of things, if you’re around my age, you (or your family) probably have a big pile of DVDs and Blu-Rays sitting around unwatched and half forgotten. Why not do a bit of amateur media preservation, rip them and upload them to your server for easier access? (Your tools for this are going to be Handbrake to do the ripping and AnyDVD to break any encryption.) I went to the trouble of ripping all my SCTV DVDs (five box sets worth) because none of it is on streaming nor could it be found on any pirate source I tried. I’m glad I did, forty years on it’s still one of the funniest shows to ever be on TV.
Part Nine/Epilogue: Sonarr/Radarr/Lidarr and Overseerr
There are a lot of ways to automate your server for better functionality or to add features you and other users might find useful. Sonarr, Radarr, and Lidarr are a part of a suite of “Servarr” services (there’s also Readarr for books and Whisparr for adult content) that allow you to automate the collection of new episodes of TV shows (Sonarr), new movie releases (Radarr) and music releases (Lidarr). They hook in to your BitTorrent client or Usenet binary newsgroup downloader and crawl your preferred Torrent trackers and Usenet indexers, alerting you to new releases and automatically grabbing them. You can also use these services to manually search for new media, and even replace/upgrade your existing media with better quality uploads. They’re really a little tricky to set up on a bare metal Ubuntu install (ideally you should be running them in Docker Containers), and I won’t be providing a step by step on installing and running them, I’m simply making you aware of their existence.
The other bit of kit I want to make you aware of is Overseerr which is a program that scans your Plex media library and will serve recommendations based on what you like. It also allows you and your users to request specific media. It can even be integrated with Sonarr/Radarr/Lidarr so that fulfilling those requests is fully automated.
And you're done. It really wasn't all that hard. Enjoy your media. Enjoy the control you have over that media. And be safe in the knowledge that no hedgefund CEO motherfucker who hates the movies but who is somehow in control of a major studio will be able to disappear anything in your library as a tax write-off.
1K notes
·
View notes
Text

Welcome back, coding enthusiasts! Today we'll talk about Git & Github , the must-know duo for any modern developer. Whether you're just starting out or need a refresher, this guide will walk you through everything from setup to intermediate-level use. Let’s jump in!
What is Git?
Git is a version control system. It helps you as a developer:
Track changes in your codebase, so if anything breaks, you can go back to a previous version. (Trust me, this happens more often than you’d think!)
Collaborate with others : whether you're working on a team project or contributing to an open-source repo, Git helps manage multiple versions of a project.
In short, Git allows you to work smarter, not harder. Developers who aren't familiar with the basics of Git? Let’s just say they’re missing a key tool in their toolkit.
What is Github ?
GitHub is a web-based platform that uses Git for version control and collaboration. It provides an interface to manage your repositories, track bugs, request new features, and much more. Think of it as a place where your Git repositories live, and where real teamwork happens. You can collaborate, share your code, and contribute to other projects, all while keeping everything well-organized.
Git & Github : not the same thing !
Git is the tool you use to create repositories and manage code on your local machine while GitHub is the platform where you host those repositories and collaborate with others. You can also host Git repositories on other platforms like GitLab and BitBucket, but GitHub is the most popular.
Installing Git (Windows, Linux, and macOS Users)
You can go ahead and download Git for your platform from (git-scm.com)
Using Git
You can use Git either through the command line (Terminal) or through a GUI. However, as a developer, it’s highly recommended to learn the terminal approach. Why? Because it’s more efficient, and understanding the commands will give you a better grasp of how Git works under the hood.
GitWorkflow
Git operates in several key areas:
Working directory (on your local machine)
Staging area (where changes are prepared to be committed)
Local repository (stored in the hidden .git directory in your project)
Remote repository (the version of the project stored on GitHub or other hosting platforms)
Let’s look at the basic commands that move code between these areas:
git init: Initializes a Git repository in your project directory, creating the .git folder.
git add: Adds your files to the staging area, where they’re prepared for committing.
git commit: Commits your staged files to your local repository.
git log: Shows the history of commits.
git push: Pushes your changes to the remote repository (like GitHub).
git pull: Pulls changes from the remote repository into your working directory.
git clone: Clones a remote repository to your local machine, maintaining the connection to the remote repo.
Branching and merging
When working in a team, it’s important to never mess up the main branch (often called master or main). This is the core of your project, and it's essential to keep it stable.
To do this, we branch out for new features or bug fixes. This way, you can make changes without affecting the main project until you’re ready to merge. Only merge your work back into the main branch once you're confident that it’s ready to go.
Getting Started: From Installation to Intermediate
Now, let’s go step-by-step through the process of using Git and GitHub from installation to pushing your first project.
Configuring Git
After installing Git, you’ll need to tell Git your name and email. This helps Git keep track of who made each change. To do this, run:

Master vs. Main Branch
By default, Git used to name the default branch master, but GitHub switched it to main for inclusivity reasons. To avoid confusion, check your default branch:

Pushing Changes to GitHub
Let’s go through an example of pushing your changes to GitHub.
First, initialize Git in your project directory:

Then to get the ‘untracked files’ , the files that we haven’t added yet to our staging area , we run the command

Now that you’ve guessed it we’re gonna run the git add command , you can add your files individually by running git add name or all at once like I did here

And finally it's time to commit our file to the local repository

Now, create a new repository on GitHub (it’s easy , just follow these instructions along with me)
Assuming you already created your github account you’ll go to this link and change username by your actual username : https://github.com/username?tab=repositories , then follow these instructions :


You can add a name and choose wether you repo can be public or private for now and forget about everything else for now.

Once your repository created on github , you’ll get this :

As you might’ve noticed, we’ve already run all these commands , all what’s left for us to do is to push our files from our local repository to our remote repository , so let’s go ahead and do that

And just like this we have successfully pushed our files to the remote repository
Here, you can see the default branch main, the total number of branches, your latest commit message along with how long ago it was made, and the number of commits you've made on that branch.

Now what is a Readme file ?
A README file is a markdown file where you can add any relevant information about your code or the specific functionality in a particular branch—since each branch can have its own README.
It also serves as a guide for anyone who clones your repository, showing them exactly how to use it.
You can add a README from this button:

Or, you can create it using a command and push it manually:

But for the sake of demonstrating how to pull content from a remote repository, we’re going with the first option:

Once that’s done, it gets added to the repository just like any other file—with a commit message and timestamp.
However, the README file isn’t on my local machine yet, so I’ll run the git pull command:

Now everything is up to date. And this is just the tiniest example of how you can pull content from your remote repository.
What is .gitignore file ?
Sometimes, you don’t want to push everything to GitHub—especially sensitive files like environment variables or API keys. These shouldn’t be shared publicly. In fact, GitHub might even send you a warning email if you do:

To avoid this, you should create a .gitignore file, like this:

Any file listed in .gitignore will not be pushed to GitHub. So you’re all set!
Cloning
When you want to copy a GitHub repository to your local machine (aka "clone" it), you have two main options:
Clone using HTTPS: This is the most straightforward method. You just copy the HTTPS link from GitHub and run:

It's simple, doesn’t require extra setup, and works well for most users. But each time you push or pull, GitHub may ask for your username and password (or personal access token if you've enabled 2FA).
But if you wanna clone using ssh , you’ll need to know a bit more about ssh keys , so let’s talk about that.
Clone using SSH (Secure Shell): This method uses SSH keys for authentication. Once set up, it’s more secure and doesn't prompt you for credentials every time. Here's how it works:
So what is an SSH key, actually?
Think of SSH keys as a digital handshake between your computer and GitHub.
Your computer generates a key pair:
A private key (stored safely on your machine)
A public key (shared with GitHub)
When you try to access GitHub via SSH, GitHub checks if the public key you've registered matches the private key on your machine.
If they match, you're in — no password prompts needed.
Steps to set up SSH with GitHub:
Generate your SSH key:

2. Start the SSH agent and add your key:

3. Copy your public key:

Then copy the output to your clipboard.
Add it to your GitHub account:
Go to GitHub → Settings → SSH and GPG keys
Click New SSH key
Paste your public key and save.
5. Now you'll be able to clone using SSH like this:

From now on, any interaction with GitHub over SSH will just work — no password typing, just smooth encrypted magic.
And there you have it ! Until next time — happy coding, and may your merges always be conflict-free! ✨👩💻👨💻
#code#codeblr#css#html#javascript#java development company#python#studyblr#progblr#programming#comp sci#web design#web developers#web development#website design#webdev#website#tech#html css#learn to code#github
93 notes
·
View notes
Text
Masterpost of informational posts
All posts are written for everyone, including those with no prior computer science education. If you know how to write an email and have used a computer at least sparingly, you are qualified for understanding these posts. :)
What is a DDoS
What are the types of malware
Vulnerabilities and Exploits (old and somewhat outdated)
Example of how malware can enter your computer
What are botnets and sinkholes
How does passwords work
Guide for getting a safer password
Here are various malware-related posts you may find interesting:
Stuxnet
The North Korean bank heist
5 vintage famous malware
Trickbot the Trickster malware (old and not up to date)
jRAT the spy and controller (old and not up to date)
Evil malware
New to Linux? Here's a quick guide for using the terminal:
Part 1: Introduction
Part 2: Commands
Part 3: Flags
Part 4: Shortcuts
If you have any questions, request for a topic I should write about, or if there is something in these posts that you don't understand, please send me a message/ask and I'll try my best to help you. :)

- unichrome
Bonus: RGB terminal
#datatag#masterpost#malware#cybersecurity#infosec#security#hacking#linux#information#informative#computer science
423 notes
·
View notes
Text
Linux update! (And a few Nvidia tips)
After a dreadful day of trying to make this work, I'm reporting that The Sims 2 finally works on my new Linux system! 😭❤️ Admittedly I have made my own life harder setting this up, but the most important thing I've learned from this experience and thought it might worth sharing:
Before you try to install TS2 on your Linux, make sure that you have your graphics card's driver updated!
When I first installed The Sims 2 on Linux it was incredibly laggy and choppy, because the default Nouveau driver didn't work well enough with my Nvidia card. After I installed the Nvidia driver from the built in driver manager, the game just straightup crashed.
Then I had to find out that Mint's driver manager couldn't install the newest driver for my card (RTX 3070), and even when installed, it didn't work. 😂
So if you have an Nvidia card and struggling or planning to install Linux in the future, below the cut are a few useful tips that I've discovered in the depths of the Internet:
Check what driver the official Nvidia site recommends for your GPU. - I did this and it showed driver version 570.
2. I think this is optional, but open your terminal and type the cmd: sudo apt update - this will trigger Linux to update its driver list.
3. Open Driver Manager, and see if the recommended driver (570 in my case is available). For me it was not available, only the 550, this was my issue.
3.1. If you can see your required driver, awesome, install it from the driver manager and skip to step 5. 3.2. If not, you have to use this PPA. -> Meaning you have to open your terminal and enter the following commands (when I list multiple commands to run, first type the first one, press enter, then type the next one, press enter etc.): sudo add-apt-repository ppa:graphics-drivers/ ppa sudo apt update You can also find installation guide on the link above, but it's basically this. 4. Now you have to restart your system, and repeat Step 3. of this list. The newest driver should show up in your Driver Manager now, install it.
5. After installing, open your terminal and type the following command: inxi -G -> this will allow us to check if the driver works properly. Shock, it did not for me :D When working properly, it should look like this:
Display: x11 server: X.Org v: 21.1.11 with: Xwayland v: 23.2.6 driver: X: loaded: nvidia gpu: nvidia,nvidia-nvswitch resolution: 1:1920x1080~60Hz 2: 1920x1080~60Hz When not working, it looks like this: Example 1: Display: x11 server: X.Org v: 21.1.11 with: Xwayland v: 23.2.6 driver: X: loaded: nouveau unloaded: fbdev,modesetting,vesa failed: nvidia
6. This is the thread that helped me fix this problem. You have to scroll down to the Nvidia Graphics troubleshooting tips.
7. I had to add this "kernel boot parameter": nvidia_drm.fbdev=1 into the system. On this link you can see how to add it either temporarily or "permanently" (meaning you don't have to add it every time you start your system, but it is removable).
To add it permanently, you have to type the following commands into your terminal:
sudo nano /etc/default/grub GRUB_CMDLINE_LINUX_DEFAULT="quiet splash nvidia_drm.fbdev=1" sudo update-grub
8. After you added it, reboot your system, and when it starts again, check if the parameter is there with the command: cat /proc/cmdline
9. If it's there, run the inxi -G command again, and see if it looks like it should.
10. If not, you might have to update the Kernel version of your Linux, which you can do in the Update Manager/View/Linux Kernels menu. I had to update mine from 6.8 to 6.11.
After all this you should be good to install the game, I made my life so much harder than it was necessarily so I hope my research on how to deal with an Nvidia Graphics card with Sims 2 on Linux is helpful to some of you. 😂
38 notes
·
View notes
Note
do you know any good guides to get into furry muck?? ive wanted to try it for ages but find it confusing
so long as you have some familiarity with command line/terminal and the basic CLI procedures, i found the starting guide on the official site quite adequate. otherwise, first familiarize yourself with the command line interface of your computer. it takes a little getting used to, but this is how the entire MUCK will be, plus knowing how to use a CLI is a good skill to have.
you will need telnet installed on your computer. telnet is the protocol that will allow you to access furrymuck through your CLI (telnet is not secure, so don't type anything into furryMUCK you wouldn't want anyone to be able to see! this is the risk of using a legacy system, assume it has already been compromised and act accordingly). on windows telnet is preinstalled but you will need to enable it as described in this guide. on linux and macOS you can install it with a package manager. i use homebrew on mac.
once you have telnet, the official guides for connecting are here. character registration is done via email. mine took around a week and a half to come back. because your passwords are sent in plaintext over email and unsecured over telnet do not reuse another password. here in the registration guide.
once you access the MUCK, the area just outside the bandstand where you start has guides for new players and the people around there are generally willing to help new and clueless players (like me). it takes a little trial and error and exploring. i found this guide for interacting with the enviornment helpful.
furryMUCK is a very magical place when you're able to meet it at its own terms. part of the fantasy is the clunkiness of the ancient internet its idiosyncrasies. have so much fun!
63 notes
·
View notes
Note
Please tell us how to get into IT without a degree! I have an interview for a small tech company this week and I’m going in as admin but as things expand I can bootstrap into a better role and I’d really appreciate knowing what skills are likely to be crucial for making that pivot.
Absolutely!! You'd be in a great position to switch to IT, since as an admin, you'd already have some familiarity with the systems and with the workplace in general. Moving between roles is easier in a smaller workplace, too.
So, this is a semi-brief guide to getting an entry-level position, for someone with zero IT experience. That position is almost always going to be help desk. You've probably heard a lot of shit about help desk, but I've always enjoyed it.
So, here we go! How to get into IT for beginners!
The most important thing on your resume will be
✨~🌟Certifications!!🌟~✨
Studying for certs can teach you a lot, especially if you're entirely new to the field. But they're also really important for getting interviews. Lots of jobs will require a cert or degree, and even if you have 5 years of experience doing exactly what the job description is, without one of those the ATS will shunt your resume into a black hole and neither HR or the IT manager will see it.
First, I recommend getting the CompTIA A+. This will teach you the basics of how the parts of a computer work together - hardware, software, how networking works, how operating systems work, troubleshooting skills, etc. If you don't have a specific area of IT you're interested in, this is REQUIRED. Even if you do, I suggest you get this cert just to get your foot in the door.
I recommend the CompTIA certs in general. They'll give you a good baseline and look good on your resume. I only got the A+ and the Network+, so can't speak for the other exams, but they weren't too tough.
If you're more into development or cybersecurity, check out these roadmaps. You'll still benefit from working help desk while pursuing one of those career paths.
The next most important thing is
🔥🔥Customer service & soft skills🔥🔥
Sorry about that.
I was hired for my first ever IT role on the strength of my interview. I definitely wasn't the only candidate with an A+, but I was the only one who knew how to handle customers (aka end-users). Which is, basically, be polite, make the end-user feel listened to, and don't make them feel stupid. It is ASTOUNDING how many IT people can't do that. I've worked with so many IT people who couldn't hide their scorn or impatience when dealing with non-tech-savvy coworkers.
Please note that you don't need to be a social butterfly or even that socially adept. I'm autistic and learned all my social skills by rote (I literally have flowcharts for social interactions), and I was still exceptional by IT standards.
Third thing, which is more for you than for your resume (although it helps):
🎇Do your own projects🎇
This is both the most and least important thing you can do for your IT career. Least important because this will have the smallest impact on your resume. Most important because this will help you learn (and figure out if IT is actually what you want to do).
The certs and interview might get you a job, but when it comes to doing your job well, hands-on experience is absolutely essential. Here are a few ideas for the complete beginner. Resources linked at the bottom.
Start using the command line. This is called Terminal on Mac and Linux. Use it for things as simple as navigating through file directories, opening apps, testing your connection, that kind of thing. The goal is to get used to using the command line, because you will use it professionally.
Build your own PC. This may sound really intimidating, but I swear it's easy! This is going to be cheaper than buying a prebuilt tower or gaming PC, and you'll learn a ton in the bargain.
Repair old PCs. If you don't want to or can't afford to build your own PC, look for cheap computers on Craiglist, secondhand stores, or elsewhere. I know a lot of universities will sell old technology for cheap. Try to buy a few and make a functioning computer out of parts, or just get one so you can feel comfortable working in the guts of a PC.
Learn Powershell or shell scripting. If you're comfortable with the command line already or just want to jump in the deep end, use scripts to automate tasks on your PC. I found this harder to do for myself than for work, because I mostly use my computer for web browsing. However, there are tons of projects out there for you to try!
Play around with a Raspberry Pi. These are mini-computers ranging from $15-$150+ and are great to experiment with. I've made a media server and a Pi hole (network-wide ad blocking) which were both fun and not too tough. If you're into torrenting, try making a seedbox!
Install Linux on your primary computer. I know, I know - I'm one of those people. But seriously, nothing will teach you more quickly than having to compile drivers through the command line so your Bluetooth headphones will work. Warning: this gets really annoying if you just want your computer to work. Dual-booting is advised.
If this sounds intimidating, that's totally normal. It is intimidating! You're going to have to do a ton of troubleshooting and things will almost never work properly on your first few projects. That is part of the fun!
Resources
Resources I've tried and liked are marked with an asterisk*
Professor Messor's Free A+ Training Course*
PC Building Simulator 2 (video game)
How to build a PC (video)
PC Part Picker (website)*
CompTIA A+ courses on Udemy
50 Basic Windows Commands with Examples*
Mac Terminal Commands Cheat Sheet
Powershell in a Month of Lunches (video series)
Getting Started with Linux (tutorial)* Note: this site is my favorite Linux resource, I highly recommend it.
Getting Started with Raspberry Pi
Raspberry Pi Projects for Beginners
/r/ITCareerQuestions*
Ask A Manager (advice blog on workplace etiquette and more)*
Reddit is helpful for tech questions in general. I have some other resources that involve sailing the seas; feel free to DM me or send an ask I can answer privately.
Tips
DO NOT work at an MSP. That stands for Managed Service Provider, and it's basically an IT department which companies contract to provide tech services. I recommend staying away from them. It's way better to work in an IT department where the end users are your coworkers, not your customers.
DO NOT trust remote entry-level IT jobs. At entry level, part of your job is schlepping around hardware and fixing PCs. A fully-remote position will almost definitely be a call center.
DO write a cover letter. YMMV on this, but every employer I've had has mentioned my cover letter as a reason to hire me.
DO ask your employer to pay for your certs. This applies only to people who either plan to move into IT in the same company, or are already in IT but want more certs.
DO NOT work anywhere without at least one woman in the department. My litmus test is two women, actually, but YMMV. If there is no woman in the department in 2024, and the department is more than 5 people, there is a reason why no women work there.
DO have patience with yourself and keep an open mind! Maybe this is just me, but if I can't do something right the first time, or if I don't love it right away, I get very discouraged. Remember that making mistakes is part of the process, and that IT is a huge field which ranges from UX design to hardware repair. There are tons of directions to go once you've got a little experience!
Disclaimer: this is based on my experience in my area of the US. Things may be different elsewhere, esp. outside of the US.
I hope this is helpful! Let me know if you have more questions!
46 notes
·
View notes
Text
Your All-in-One AI Web Agent: Save $200+ a Month, Unleash Limitless Possibilities!
Imagine having an AI agent that costs you nothing monthly, runs directly on your computer, and is unrestricted in its capabilities. OpenAI Operator charges up to $200/month for limited API calls and restricts access to many tasks like visiting thousands of websites. With DeepSeek-R1 and Browser-Use, you:
• Save money while keeping everything local and private.
• Automate visiting 100,000+ websites, gathering data, filling forms, and navigating like a human.
• Gain total freedom to explore, scrape, and interact with the web like never before.
You may have heard about Operator from Open AI that runs on their computer in some cloud with you passing on private information to their AI to so anything useful. AND you pay for the gift . It is not paranoid to not want you passwords and logins and personal details to be shared. OpenAI of course charges a substantial amount of money for something that will limit exactly what sites you can visit, like YouTube for example. With this method you will start telling an AI exactly what you want it to do, in plain language, and watching it navigate the web, gather information, and make decisions—all without writing a single line of code.
In this guide, we’ll show you how to build an AI agent that performs tasks like scraping news, analyzing social media mentions, and making predictions using DeepSeek-R1 and Browser-Use, but instead of writing a Python script, you’ll interact with the AI directly using prompts.
These instructions are in constant revisions as DeepSeek R1 is days old. Browser Use has been a standard for quite a while. This method can be for people who are new to AI and programming. It may seem technical at first, but by the end of this guide, you’ll feel confident using your AI agent to perform a variety of tasks, all by talking to it. how, if you look at these instructions and it seems to overwhelming, wait, we will have a single download app soon. It is in testing now.
This is version 3.0 of these instructions January 26th, 2025.
This guide will walk you through setting up DeepSeek-R1 8B (4-bit) and Browser-Use Web UI, ensuring even the most novice users succeed.
What You’ll Achieve
By following this guide, you’ll:
1. Set up DeepSeek-R1, a reasoning AI that works privately on your computer.
2. Configure Browser-Use Web UI, a tool to automate web scraping, form-filling, and real-time interaction.
3. Create an AI agent capable of finding stock news, gathering Reddit mentions, and predicting stock trends—all while operating without cloud restrictions.
A Deep Dive At ReadMultiplex.com Soon
We will have a deep dive into how you can use this platform for very advanced AI use cases that few have thought of let alone seen before. Join us at ReadMultiplex.com and become a member that not only sees the future earlier but also with particle and pragmatic ways to profit from the future.
System Requirements
Hardware
• RAM: 8 GB minimum (16 GB recommended).
• Processor: Quad-core (Intel i5/AMD Ryzen 5 or higher).
• Storage: 5 GB free space.
• Graphics: GPU optional for faster processing.
Software
• Operating System: macOS, Windows 10+, or Linux.
• Python: Version 3.8 or higher.
• Git: Installed.
Step 1: Get Your Tools Ready
We’ll need Python, Git, and a terminal/command prompt to proceed. Follow these instructions carefully.
Install Python
1. Check Python Installation:
• Open your terminal/command prompt and type:
python3 --version
• If Python is installed, you’ll see a version like:
Python 3.9.7
2. If Python Is Not Installed:
• Download Python from python.org.
• During installation, ensure you check “Add Python to PATH” on Windows.
3. Verify Installation:
python3 --version
Install Git
1. Check Git Installation:
• Run:
git --version
• If installed, you’ll see:
git version 2.34.1
2. If Git Is Not Installed:
• Windows: Download Git from git-scm.com and follow the instructions.
• Mac/Linux: Install via terminal:
sudo apt install git -y # For Ubuntu/Debian
brew install git # For macOS
Step 2: Download and Build llama.cpp
We’ll use llama.cpp to run the DeepSeek-R1 model locally.
1. Open your terminal/command prompt.
2. Navigate to a clear location for your project files:
mkdir ~/AI_Project
cd ~/AI_Project
3. Clone the llama.cpp repository:
git clone https://github.com/ggerganov/llama.cpp.git
cd llama.cpp
4. Build the project:
• Mac/Linux:
make
• Windows:
• Install a C++ compiler (e.g., MSVC or MinGW).
• Run:
mkdir build
cd build
cmake ..
cmake --build . --config Release
Step 3: Download DeepSeek-R1 8B 4-bit Model
1. Visit the DeepSeek-R1 8B Model Page on Hugging Face.
2. Download the 4-bit quantized model file:
• Example: DeepSeek-R1-Distill-Qwen-8B-Q4_K_M.gguf.
3. Move the model to your llama.cpp folder:
mv ~/Downloads/DeepSeek-R1-Distill-Qwen-8B-Q4_K_M.gguf ~/AI_Project/llama.cpp
Step 4: Start DeepSeek-R1
1. Navigate to your llama.cpp folder:
cd ~/AI_Project/llama.cpp
2. Run the model with a sample prompt:
./main -m DeepSeek-R1-Distill-Qwen-8B-Q4_K_M.gguf -p "What is the capital of France?"
3. Expected Output:
The capital of France is Paris.
Step 5: Set Up Browser-Use Web UI
1. Go back to your project folder:
cd ~/AI_Project
2. Clone the Browser-Use repository:
git clone https://github.com/browser-use/browser-use.git
cd browser-use
3. Create a virtual environment:
python3 -m venv env
4. Activate the virtual environment:
• Mac/Linux:
source env/bin/activate
• Windows:
env\Scripts\activate
5. Install dependencies:
pip install -r requirements.txt
6. Start the Web UI:
python examples/gradio_demo.py
7. Open the local URL in your browser:
http://127.0.0.1:7860
Step 6: Configure the Web UI for DeepSeek-R1
1. Go to the Settings panel in the Web UI.
2. Specify the DeepSeek model path:
~/AI_Project/llama.cpp/DeepSeek-R1-Distill-Qwen-8B-Q4_K_M.gguf
3. Adjust Timeout Settings:
• Increase the timeout to 120 seconds for larger models.
4. Enable Memory-Saving Mode if your system has less than 16 GB of RAM.
Step 7: Run an Example Task
Let’s create an agent that:
1. Searches for Tesla stock news.
2. Gathers Reddit mentions.
3. Predicts the stock trend.
Example Prompt:
Search for "Tesla stock news" on Google News and summarize the top 3 headlines. Then, check Reddit for the latest mentions of "Tesla stock" and predict whether the stock will rise based on the news and discussions.
--
Congratulations! You’ve built a powerful, private AI agent capable of automating the web and reasoning in real time. Unlike costly, restricted tools like OpenAI Operator, you’ve spent nothing beyond your time. Unleash your AI agent on tasks that were once impossible and imagine the possibilities for personal projects, research, and business. You’re not limited anymore. You own the web—your AI agent just unlocked it! 🚀
Stay tuned fora FREE simple to use single app that will do this all and more.

7 notes
·
View notes
Text
i will say. learning linux is not scary and it's not hard. i only use linux casually on a secondary machine and i've become pretty proficient at it, enough to guide someone else when using the terminal.
however. we can't be pretending that linux distros are user friendly, because they straight up aren't. even when using linux mint, i have to open up my computer's neurons and rewire them every couple of weeks. when i was using endeavouros i had to crawl along the guts of the operating system to get my drives to auto mount and it didn't work and caused my computer to take 2 full minutes to shut down.
it wasn't hard, it was a Pain In The Ass and this is the problem with pitching linux to literally anyone
4 notes
·
View notes
Note
computer/firefox anon, no questions this time. just my undying thanks! as tumblr users say, i am kissing you on the mouth etc etc. huge thank you to you and everyone else who added stuff in the replies or reblogs — i feel much more confident about this now<33. tldr: y’all are awesome, thanks a bunch!
happy to help! and i think i said this deep down under the read-more in the first response to your Linux ask, but it's worth highlighting--@compusever's advice to get a Windows 10 or 11 Home laptop and do what you can with the privacy settings is not AT ALL incompatible with trying Linux or eventually replacing Windows with it. once you've booted up the computer from an installation USB drive, most distros will offer a temporary "preview" version of the OS that runs from the USB drive without changing anything on the computer. you can try Ubuntu, mess around, see if you like it, wipe the USB drive, put Mint on it, and try that; if you go for the full install you can dual-boot and keep Windows around in hard-drive quarantine in case you need it.
in other words, you don't have to take the entire plunge all at once! but i suspect that if you don't have pre-existing desktop UI preferences, and you strongly prefer a device that won't pester/spy on/micromanage you, a beginner-friendly Linux will be easier to use than any of the current versions of Windows.
btw, here's the install guide for Mint: https://linuxmint-installation-guide.readthedocs.io/en/latest/ compared to the Ubuntu one, which goes out of its way to be friendly and dead simple, the Mint guide is... a lot closer to what you can expect from most Linux tutorials, lmao. i especially love that the very second step explains a bit about why it wants you to check that the file didn't get corrupted in the download process, immediately starts providing commands you can copy into a Linux terminal to generate cryptographic checksums, and only then adds a "how to do this on Windows" link... to a forum post with commands you can paste into a Windows terminal. (meanwhile, Ubuntu gives you a download link and then displays an unobtrusive "here's how to verify the file if you want" with a one-off command and a link to more info.) even the friendliest Linux tends to be built on the labor of absolute nerds who are into this stuff as a hobby, and they are very helpful, but be warned that they often have a wildly skewed frame of reference about what "normal computer use" consists of.
51 notes
·
View notes
Text
Building Your Own Operating System: A Beginner’s Guide
An operating system (OS) is an essential component of computer systems, serving as an interface between hardware and software. It manages system resources, provides services to users and applications, and ensures efficient execution of processes. Without an OS, users would have to manually manage hardware resources, making computing impractical for everyday use.

Lightweight operating system for old laptops
Functions of an Operating System
Operating systems perform several crucial functions to maintain system stability and usability. These functions include:
1. Process Management
The OS allocates resources to processes and ensures fair execution while preventing conflicts. It employs algorithms like First-Come-First-Serve (FCFS), Round Robin, and Shortest Job Next (SJN) to optimize CPU utilization and maintain system responsiveness.
2. Memory Management
The OS tracks memory usage and prevents memory leaks by implementing techniques such as paging, segmentation, and virtual memory. These mechanisms enable multitasking and improve overall system performance.
3. File System Management
It provides mechanisms for reading, writing, and deleting files while maintaining security through permissions and access control. File systems such as NTFS, FAT32, and ext4 are widely used across different operating systems.
4. Device Management
The OS provides device drivers to facilitate interaction with hardware components like printers, keyboards, and network adapters. It ensures smooth data exchange and resource allocation for input/output (I/O) operations.
5. Security and Access Control
It enforces authentication, authorization, and encryption mechanisms to protect user data and system integrity. Modern OSs incorporate features like firewalls, anti-malware tools, and secure boot processes to prevent unauthorized access and cyber threats.
6. User Interface
CLI-based systems, such as Linux terminals, provide direct access to system commands, while GUI-based systems, such as Windows and macOS, offer intuitive navigation through icons and menus.
Types of Operating Systems
Operating systems come in various forms, each designed to cater to specific computing needs. Some common types include:
1. Batch Operating System
These systems were widely used in early computing environments for tasks like payroll processing and scientific computations.
2. Multi-User Operating System
It ensures fair resource allocation and prevents conflicts between users. Examples include UNIX and Windows Server.
3. Real-Time Operating System (RTOS)
RTOS is designed for time-sensitive applications, where processing must occur within strict deadlines. It is used in embedded systems, medical devices, and industrial automation. Examples include VxWorks and FreeRTOS.
4 Mobile Operating System
Mobile OSs are tailored for smartphones and tablets, offering touchscreen interfaces and app ecosystems.
5 Distributed Operating System
Distributed OS manages multiple computers as a single system, enabling resource sharing and parallel processing. It is used in cloud computing and supercomputing environments. Examples include Google’s Fuchsia and Amoeba.
Popular Operating Systems
Several operating systems dominate the computing landscape, each catering to specific user needs and hardware platforms.
1. Microsoft Windows
It is popular among home users, businesses, and gamers. Windows 10 and 11 are the latest versions, offering improved performance, security, and compatibility.
2. macOS
macOS is Apple’s proprietary OS designed for Mac computers. It provides a seamless experience with Apple hardware and software, featuring robust security and high-end multimedia capabilities.
3. Linux
Linux is an open-source OS favored by developers, system administrators, and security professionals. It offers various distributions, including Ubuntu, Fedora, and Debian, each catering to different user preferences.
4. Android
It is based on the Linux kernel and supports a vast ecosystem of applications.
5. iOS
iOS is Apple’s mobile OS, known for its smooth performance, security, and exclusive app ecosystem. It powers iPhones and iPads, offering seamless integration with other Apple devices.
Future of Operating Systems
The future of operating systems is shaped by emerging technologies such as artificial intelligence (AI), cloud computing, and edge computing. Some key trends include:
1. AI-Driven OS Enhancements
AI-powered features, such as voice assistants and predictive automation, are becoming integral to modern OSs. AI helps optimize performance, enhance security, and personalize user experiences.
2. Cloud-Based Operating Systems
Cloud OSs enable users to access applications and data remotely. Chrome OS is an example of a cloud-centric OS that relies on internet connectivity for most functions.
3. Edge Computing Integration
With the rise of IoT devices, edge computing is gaining importance. Future OSs will focus on decentralized computing, reducing latency and improving real-time processing.
4. Increased Focus on Security
Cyber threats continue to evolve, prompting OS developers to implement advanced security measures such as zero-trust architectures, multi-factor authentication, and blockchain-based security.
3 notes
·
View notes
Text
jesus christ, windows 11 is a mess. I was helping my grandpa to get his pc running faster, only to discover the reason that it slowed down to unusable speeds in the first place is windows 11's constant bloatware, and tracking, and half of the os being a useless as fuck ai. None of this can easily be disabled btw, online guides say to use the group policy editor, but thats not available on home, and also no longer installable, so the only option is to go mess with the registry editor and hope it works. (Which, btw comes with the potential of bricking the pc).
I'm fairly versed in computers, I'm familiar with the command prompt and powershell, and all that, and in my everyday life, I use a linux computer for work, and I do less terminal based things for settings on my linux pc than I just did on this windows pc. Windows 11 is so fucking useless, it assumes any computer running it has insane cpu and ram capacity, just to fill all that up with adds, and not even anything usefull
3 notes
·
View notes
Note
Ahrah: @dragongirlcock encouraged us to tell you that we've recently made the permanent jump from Windows to Linux. Your post on the topic on top of the usual Microsoft bullshit was one of the catalysts to just do it now. We did play around with several different distros in 2013 in a dual boot system, so we already had a feel for a few different ones and what we prefer in a DE and whatnot. They were all Debian based, but then we happened to stumble across Garuda KDE Dr460nized, and aside from that we really like KDE Plasma, couldn't possibly pass up on a distro with that name XD Plus it has been nice having most gaming things working out of the box and generally saved us some floundering in figuring out what all we needed, bc things have come a long way since 2013.
We've been having bit of a time trying to learn the terminal and all, and have been running into miscellaneous issues, but it has been comforting to have more expirienced people we know look at them and go, "that problem is Weird wtf???"
Sometimes we'll go looking for info and the internet is like, "Ubuntu = Linux, especially if you're a newbie, and here's how to do things without having to touch the big scary terminal :) " and anything that might be helpful it feels like there's the expectation that you know everything already if you're on Arch. *angry dragon noises*
We feel like we've somehow happened to slip through the cracks of what people "typically" do or are encouraged to do when it comes to transitioning to Linux, why is this? Bc I feel that us having more of an interest in learning more shouldn't be that odd, it seems stranger to me that there seems to be a Windows vs Mac parallel with Debian vs Arch in terms of the general information available and expectations??? Also any recommentions on ways to just stumble upon things would be helpful. Bc sure we can got to the AUR, but you have to kind of already know what you're looking for.
hell yeah !!! welcome to The Community !! (programmer socks optional d: )
oooooohhh garuda !! recognised the name and is bc it's built atop arch !!
yeag, the ubuntu-as-default assumptions (which, annoyingly, even affects debian users sometimes) are frustrating. also the "commands scawy uwu" attitude (which also seems to include "just paste this magic command in the terminal dw it's totally fine :))))" from time to time) is frustrating as well.
i don't expect every single person to manually install arch, or like gentoo or smth, spend a week configuring it, and fuckign write an emacs port to run it as a full wayland compositor, but treating computers as Magical Boxes and users as Inherently Inept really gets my goat.
idk what good communities look like anymore bc i'm not part of any and solve shit myself or by asking friends/partners, but for arch, the official wiki tends to have most things well-explained. it's not a complete solution but it should help 🩷
in conjunction w/ the arch wiki, we use stackoverflow, man pages (documentation that doesn't require a website 7 months pregnant w/ javascript octuplets ? gooodddsss it feels good), package manager search, chaotic-aur (has most aur packages pre-compiled as an additional repo, so pacman can search and install them), tldr which is simplified man pages (very handy for example commands !!)
linux systems really are a thousand rats in a trench coat, so understanding what rats ya got helps but can take time. the best way round that is have a system you can break.
for like getting from ubuntu-coded to arch-coded, we're planning some GUIDEs that may be handy. wanna cover basic terminal and shell stuff, standard unix commands, what some of the bigger trenchcoat rats are and why.
until then, if there's any specific questions feel free to drop a message here or in DMs or wherever 🩷
4 notes
·
View notes
Text
How to host local Club Penguin Private Server (CPPS) on Silicon Mac (M1/M2/M3) thru play.localserver & Solero's Wand install.
I spent so long looking for a solution to this that I want to contribute what worked for me. I got so frustrated looking for something that worked, and I hope this guide will help others avoid that frustration.
This is NOT a guide on hosting or serving a CPPS. This is a guide on making a CPPS playable by locally hosting your server on your Silicon M1/M2/M3 Macbook. This worked on my M3 Macbook, and, in my experience, it seems the newer the hardware/operating system gets, the harder it is accomplish this.
DISCLAIMER *I do not know very much about this topic. I can paste commands into terminal and execute them, I know how to install DMG files I downloaded from the internet (the bar is in hell, I am aware), and I know how to enter play.localhost to run this in a browser. I am no expert; this guide is for beginners like myself who want a CPPS. This is beginner-level stuff. If you want advice or need help hosting, refer to the Wand Github page, Solero's Dash (an actual web-hosting solution for Houdini/Wand), Solero's discord, or, when in doubt, Google it. (I recommend only asking for help in Solero's discord for help AFTER trying your best to search for a solution, and even after that, trying to search key terms in their chat logs. They often have to repeat the same advice over, and over, and over again.)*
TLDR; IDK shit about shit
USING WAND INSTALLER
wand description from github: Wand makes it easy to configure dash, houdini and a media server utilizing docker & docker-compose.
All the assets are located here.
Installation instructions from the above link:
Installation script 1. run the script: bash <(curl -s https://raw.githubusercontent.com/solero/wand/master/install.sh) 2. Answer Questions which are: Database password (Leave blank for random password) Hostname (example: clubpenguin.com) (Leave empty for localhost) External IP Address (Leave empty for localhost) 3. Run and enjoy. Run this command: $ cd wand && sudo docker-compose up
The steps I took:
1. Install Docker via Terminal & Homebrew.
Installing the Docker DMG file did not work properly when I tried. I realized later that Docker is seperate from Docker Desktop (the DMG file). I got Docker to work by using Terminal to install Homebrew, and then using Homebrew to install Docker.
Indented text = paste into Terminal.
Command to install Homebrew:
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
Ensure Homebrew is installed:
brew --version
Install Docker:
brew install docker
Recommended: Install Docker Desktop (useful in determining if your server is running, stopped, or stuck in a restart loop).
brew install --cask docker
Run Docker Desktop:
open -a Docker
2. Run installation script:
bash <(curl -s https://raw.githubusercontent.com/solero/wand/master/install.sh)
From Github instructions:
Answer Questions which are:
Database password (Leave blank for random password)
Hostname (example: clubpenguin.com) (Leave empty for localhost)
External IP Address (Leave empty for localhost)
3. $ cd wand && sudo docker-compose up
This is what is provided in the Github. This command didn't work on Mac; I believe it's formatted for Linux OS. Here's how I broke it up and enabled it to run from Mac's Terminal.
Navigate to Wand directory:
cd wand
Double-check if you're in the right directory:
ls
Start Docker container:
docker-compose up
If the above doesn't work, try
docker compose up
or
brew install docker-compose
Takes a second...

Ensure Docker is running:
docker info
If it isn't, open the Docker Desktop application.
*After using compose up, this error may appear:*
WARN[0000] /Users/[user]/wand/docker-compose.yml: the attribute version is obsolete, it will be ignored, please remove it to avoid potential confusion
This is harmless. If you get annoyed by errors, this can be solved by:
nano docker-compose.yml

See Version 3.7 at the top? Delete that line.
Ctrl-X (NOT COMMAND-X) to exit, Y to save, Enter.
PLAY.LOCALHOST
Type http://PLAY.LOCALHOST into a browser.

Create a penguin.

Try logging in that penguin:

This step was agony. I'm not savvy with running obsolete or deprecated software, and, of course, Club Penguin (and Houdini/Wand's assest) uses Flash, which was discontinued, and timebombed by Adobe, in 2021.
I tried Ruffle. Club Penguin Journey uses Ruffle, so why can't I?
Running Ruffle in Firefox:


No luck.
In the Solero discord, they'll direct to this blog post:

This method does not work on Mac M1/M2/M3. The program is "out of date" and you cannot run it. It works on Macbook's running Sonoma and backward. I'm on an M3 running Sequoia.
they'll often post this video in the discord:

In theory, this method should work, and it does for many, but for whatever reason, not on my M3. I tried different versions of Ungoogled, I tried so many different patches of Pepperflash, and it never cooperated. I tried Pepperflash, I tried Fast Patch!, I tried dedicated Flash browsers, running Flash plugins for Pale Moon, Ungoogled, Waterfox, but I could never get past him.

Every time I see this stupid penguin's face I'm filled with rage. But I am going to save you that rage!!!
If you get this method to work, yay! I could not. Maybe I don't know enough about patching, maybe I'm a little tech stupid.
WHAT WORKED: Using a dedicated CPPS desktop application that allows you to plug in a URL.
I give you...

He is your solution, your answer to
I discovered this solution through Solero's Discord, when someone answered a question re: playing online.

Waddle Forever was not what I was looking forever, but I noticed in their credits:
The electron client is originally forked from the Club Penguin Avalanche client. The server is based in solero's works in reverse engineering the Club Penguin server (Houdini server emulator). The media server is also mostly from solero's media servers.
And that's how I found out the solution: Using CPA Client
Download the CPAvalanche Client
It runs Adode Flash x64. Easy peasy.
(the instructions are in Portuguese, but for English users:
Navigate to releases.

And download this one:

Once downloaded, open.

Drag into applications.
Run http://play.localhost through the client:
Open CPAvalanche Client. It will direct you to CPAvalance once loaded, but you're here because you want to play play.localhost.
Navigate to CPAvalanche Client next to your Apple. Click Mudar a URL do Club Penguin.

Press Sim.

URL: http://play.localhost
Ok.

Press Login once the page loads, and...

That's it! No more penguin! Have fun :)
CREDITS:
Solero Discord / Waddle Forever / Wand / CPA Client / Solero.Me
#solero/wand#wand#solero#cpps#club penguin private server#cpps localhost#club penguin#macbook#macbook silicon#mac m1#mac m2#mac m3#apple silicon
2 notes
·
View notes
Note
Since you use Arch:
1) What made you choose Arch?
2) How hard is it to use?
3) If you do that, how hard is it to dual boot with Arch?
(I think many/maybe most Linux OS have documentation, but I'm not very familiar with Arch other than the memes. My main debugging skills are looking stuff up and asking people, in that order)
(The 3 distros on top of my to-try list are Debian, Mint, and Arch. I'd be delighted to have a reason to put one of them higher on the list.)
1. The size of the repository. With the AUR plus the already large official repository practically every program no matter how niche is one command away. And also the documentation is fucking incredible. I've been trying out Debian lately but honestly I might switch back because its repository sucks (latest neovim version is 6.x????) And the documentation is awfulllll.
2. Just as easy as every other distro. Also since you set up the environment you can tune it to your need. I tend to work exclusively through a terminal so I rock a super minimal setup.
Setup can be kinda tricky, installing is a process but the guide is very easy to follow, and there is also the archinstall script that makes the process way way simpler.
Setting up your environment is a rabbit hole but it's mostly installing programs and setting then up. You can install a display manager and KDE and have a totally fine easy to use experience with next to how effort. And while setting up I can practically guarantee the wiki has a detailed page with all the info you may need.
TL;DR the install process can be complex, setting up a desktop environment is super easy, and using it is very easy.
3. Dual Booting is either super simple. Or genuinely the hardest thing you can do with linux. If you dont mind manually opening the bios and switching the boot source to switch its easy.
If you want to be able to launch windows from GRUB without opening the bios prepare for hell on earth. When I tried it, it took a week and I never got it to work. And it's very easy to fuck up your boot loader and fixing that is extremely difficult with few resources online.
I personally
18 notes
·
View notes
Note
can i ask how you installed linux on your laptop? ive been thinking about doing it for a while but dont really know what i need to do to prep for it
I'm just a beginner too so I totally understand how confusing it all seems but it's not too bad if you take your time! This is going to be as quick as possible, and I'm going to assume you're choosing the Linux Mint version of Linux because it's a widely accepted opinion that it's the best for people new to this OS. (You can always add another version of Linux or change to it later on once you've had success with this!)
Note: You'll need a USB stick with at least 4GB on it, and you will want to have it dedicated to the Linux install
Back everything up! How you do this is up to you. I did it by saving anything important to an External HD (I already have a clean install of windows on a CD). If you don't have a clean install of your current OS, you can burn a restore point to a CD or DVD, or put it on a USB stick. Note: You'll be able to access all of your files on your current harddrive even after partitioning and booting on Linux! So you don't need to make two copies or transfer things over. If you have an account for your browser, sync your tabs/passwords/history/etc for a muuuuch smoother transition! Linux comes with Firefox already installed, so if you don't currently use it but want to make the change, you can port your bookmarks in from Chrome.
Get information about your system: You'll want to know your current OS (mine was Windows 7), what graphics card you have, how much RAM (memory) your computer has, and what kind of booting your system does (BIOS or UEFI), and of course, how much space on your harddrive there is. Note: I use "harddrive" to mean wherever you're installing your OS, some people install it on an external HD, or an SSD and run it from there.
Pick which distribution of Linux to install: While you can install whichever one you want, Linux Mint is the safest bet for someone new to Linux - if your computer can run a Windows or Mac OS, it can run the version of Linux Mint called Cinnamon. And that's the one that's the most user friendly. It's a great way to learn how to use the Terminal (like command prompts on Windows) in a low stress way because you still have the User Interface. It also has a robust community with plenty of information/resources out there! Super helpful. If your computer doesn't have enough space (though Cinnamon does not take up much at all, I think people say something around 165GB for Linux Mint Cinnamon), Mate is smaller and XCFE is the smallest, though they are less beginner friendly.
Decide how you want to install it: Here is an installation guide I used to get Linux Mint. Some of it I had to read a few times and only really understood once I did it, but with my backups I did it without fear. I recommend doing a Dual Boot system if you have the space, partitioning your hard drive is not nearly as complicated as I thought it'd be and also it's good for if Linux doesn't have a version for some programs you like to use. Here's another installation guide, though I think it only focuses on going from Windows to Linux. It has some great tips for post-installation though if you're not going from Windows. It also assumes you didn't pre-partition your harddrive. I partitioned mine before installation so I used the "Something Else" option when it asked me which type of install I wanted. There are instructions on that in the first installation guide! P.s. - If you're on Windows 7, the recommended USB writer program isn't available for you. I used USBImager!
Wrap up any loose ends and do web searches for anything you're not sure of. Bring things up on your phone for reference while you're mid-install. NOTE: When you boot your computer from the USB Stick with Linux Mint on it (I'm assuming other varieties of Linux too?), you have the option to try it out without installing it. Then while you're trying it out if you're ready to install it, there's an icon on the desktop you click. If you don't install it, none of your settings or anything will save and the next time you boot from the USB stick it'll be a fresh version of Linux.
https://forums.linuxmint.com/ There are mountains of information in here! And plenty of them are helpful for beginners. https://easylinuxtipsproject.blogspot.com/p/first-mint-cinnamon.html This is helpful too!!! The whole site is.
If you don't like how something looks/feels/works, there's probably a system setting for it. Do a Timeshift snapshot when you first install Linux, then one after you've spent time setting everything up! That way you're covered. After you do that second Timeshift you can start looking for programs to install if you'd like! Definitely look up tutorials/etc on that.
Okay I hope this was enough to get your started and cover a lot of bases! Remember to have patience, re-read stuff, take breaks if you're confused, and that like a million people use Linux Mint successfully so once you get through the hard part (pre-install and installing) it's pretty smooth sailing.
Let me know if you have anymore questions!
2 notes
·
View notes